hook的并发症
可以理解成一个有意思的问题,假如地址 addr1 上有一个函数func1,长度为len, 将这个函数 整体换一个位置,挪到 addr2, 移动之后的函数成为func2
1 | memcpy(addr2 ,addr1,len ); |
原来调用 func1 语法是:
1 | func1(arg1 , arg2 , arg3); |
问:
现在用如下的方式调用 func2 是否会发生异常?
1 | func2(arg1 , arg2 , arg3); |
假如把 func1 的开头 修改为特定的 shellcode,改成 跳转 + 目标跳转地址(比如 0xFF2500000000 + func_addr)的格式,就是传统的 inline hook, 但是这种hook将 原来函数的指令 挪了位置,再次调用有的时候会崩溃, 有的时候称这种情况为 hook的 并发症。
思路
==以下仅讨论 x86_64的情况,不涉及arm及其他体系结构。==
函数内部是一条条的指令及其数据,比如:
1 | 402e30: 55 push %rbp |
我们把func1整体挪了一个位置,挪到了func2, 还是原来的指令,比如 55 48 49 e5 顺序和值都和原来一样,但是按照 调用func1的方式调用 func2, 程序有的时候会崩溃,在找个例子里,程序会在
1 | callq 4095e6 <_ZN19ZoneActRunActCmdReqC1Ev> |
这个地方崩溃。
其根本原因,是这些程序是 rip relative 的指令,类似于 call lea mov 等指令操作的指令有时候是相对于 PC(rip) 的偏移,CPU 执行 func1的 指令 PC 与 执行 func2的 的PC 是不一样的,也就是 rip寄存器的值 不一样,rip寄存器的值 + 指令指定的偏移 offset ,就是实际的偏移地址。
上面的例子里面, 0x4095e6 是函数 _ZN19ZoneActRunActCmdReqC1Ev 的地址, 调用 _ZN19ZoneActRunActCmdReqC1Ev 就是 把 rip 转到0x4095e6, 具体到字节是:
1 | 402e60: e8 81 67 00 00 |
我们模拟cpu 执行到当前的位置,(%rip) = 0x402e60, 这条指令有 5 个字节, 其中 e8 是 call 的opcode, 81 67 00 00 这四个字节 是偏移地址,
下一条指令(rip next)的地址是:
1 | 402e65: 48 8d 4d e0 lea -0x20(%rbp),%rcx |
rip_next = 0x402e65, CPU并不是直接计算出 _ZN19ZoneActRunActCmdReqC1Ev 的地址,而是按照 rip_next + offset 进行编码 指令中的偏移 :
可以看到,rip 和rip_next 如果挪动了,offset 没变, dest_func_addr 会是一个错误的值; 我们如果把 offset调整为 相对于 func2里面rip相对的 正确的 offset, 那么函数func2 就 跟 func1 一样了,可以正常调用。
提到的 修正 offset的方式,就是修正 rip relative 的指令的偏移,一般在 inline hook的时候,会有指令的替换和挪动位置,指令调整是 解决这类并发症的一个方式,有成熟的hook库 完成了这类操作,比如polyhook, 其中的一个特性就是 解决了 inline Hook中的 rip relative 的指令的 位移修正。
那么,如何修正rip relative指令呢?
- 需要找到 哪些指令会涉及rip relative
- 如何找到 rip relative 指令
- rip relative指令中,位移是哪些字段,是8位的还是16位的,还是32位的
- offset 要如何修正到 正确的值
要解决上面的问题,其中一个很基本的问题 就是要认识 CPU的指令集及其格式,找出要修正的指令,解析格式,找出 offset 进行修正。
那么,需要学一下 CPU的指令集,参考的东西比较少,主要是Intel的CPU文档。
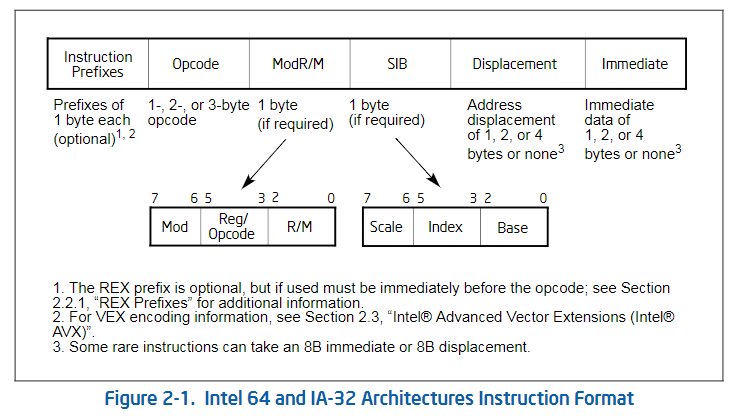
指令格式概述
指令包括可选的指令前缀 (in any order),主要操作码字节 (up to three bytes),由ModR / M字节以及有时由SIB(Scale-Index-Base)组成的寻址形式说明符 (if required) ,位移字段 (if required)和立即数据字段 (if required)。
最基础的 指令结构是这样的:
不过现在我们基本都进入64位了,新增了64位的 rex 前缀 扩展,当然 rex prefix 是可选的 不一定有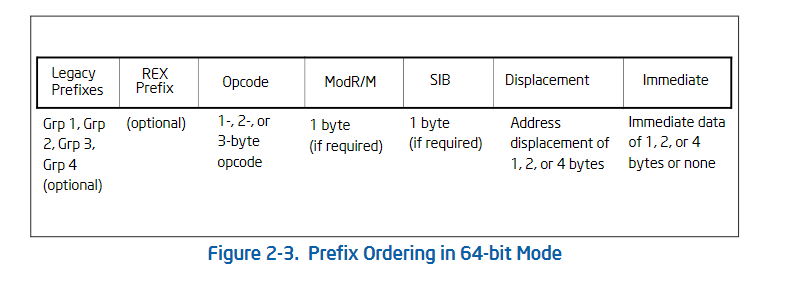
我们来具体的看一下 其中的每个部分。
Instruction Prefixes
指令前缀码,不包括 REX 前缀码部分

opcode

ModR/M and SIB Bytes
很多指令都是有操作数的,寻址是个很频繁的操作,操作数可以是立即数、寄存器、内存地址,或者是几种操作数的组合,ModR/M and SIB Bytes 表示的是 寻址模式标识字节,不是特别好理解,通过一个例子看一下:
1 | 40c27a: 8b bd c4 62 00 00 mov 0x62c4(%rbp),%edi |
发现, mov %eax,%ecx 这条指令 用了两个字节编码,其中,89 是mov 的opcode,可以理解 代表mov, 那么后面的 C1 就代表其操作数了,
看一下 C1 :
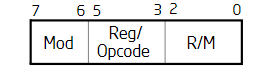
1 | C1: 11 000 001 |
对于使用到 ModR/M表示 寻址操作数的,对用一张 CPU的 寻址表,给出了对应的 表示规则,如图, 可以看到 mov %eax,%ecx 是怎么表示的。
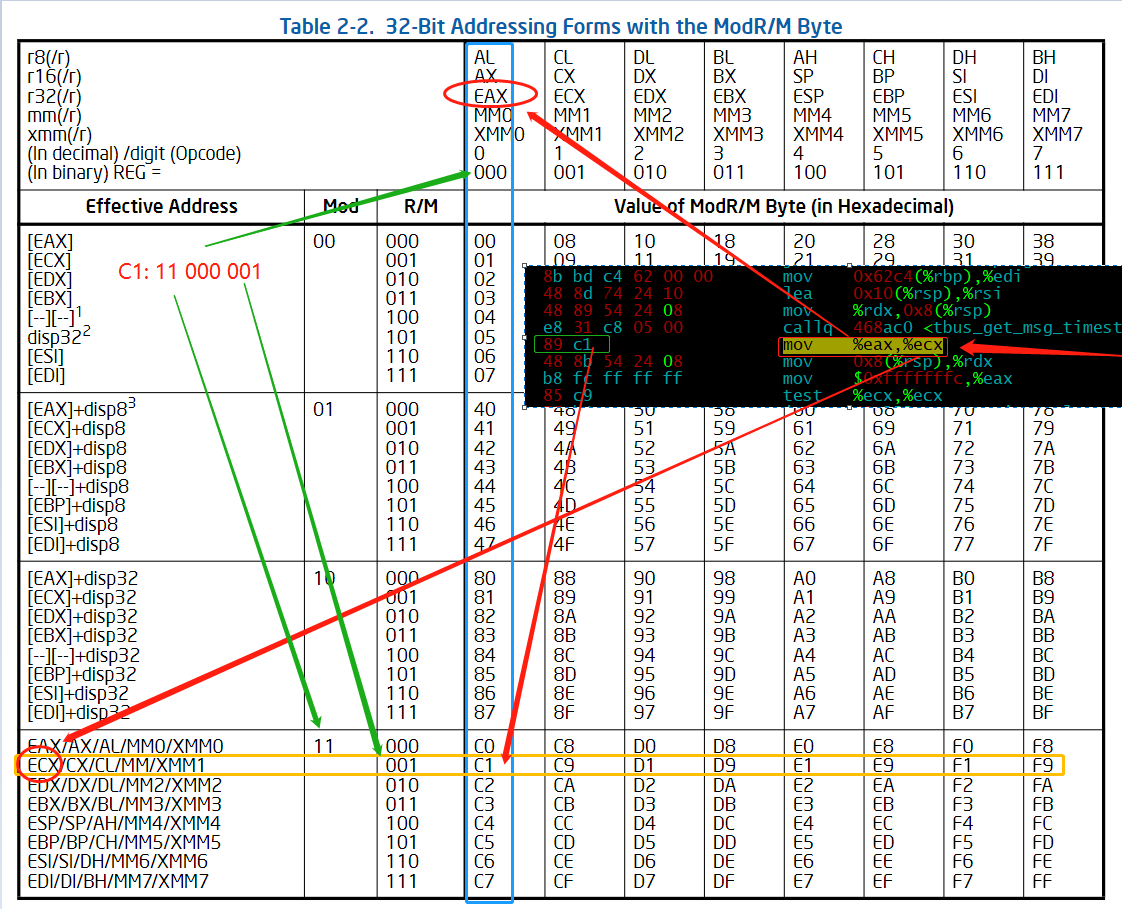
某些特定的ModR/M字节需要一个后续字节,称为SIB字节。32位指令的基地址+偏移量,以及 比例*偏移量 的形式的寻址方式需要SIB字节。 SIB字节包括下列信息:
- scale(比例)域指定了放大的比例。
- index(偏移)域指定了用来存放偏移量 的寄存器。
- base (基地址)域用来标识存放基地址的寄存器。
也是用于操作数操作的,比如
1 | mov (%ecx*4+%eax) , %edi |
类似这种有放大比例,就需要用到SIB字节来表示。对应的 同样有一个 SIB 编码的表:
不过我统计了一下,类似这种指令生成的不多,编译器应该偏向于生成 短小易于编解码的 指令,两个短的比一个长的 执行的机器周期短。
REX Prefixes 开启64位计算的基石
AMD 在x86体系的32位计算扩展为64位计算, AMD64体系的64位计算是这样设计:操作数的Default Operand-Size是32位,而Address-Size是固定为64位的,这里就引发3个问题要解决的:
- 问题1:当要访问是64位的寄存器时,那么必须要有一种机制去开启或者说确认访问的寄存器是64位的。
- 问题2:而要访问的内存操作数寄存器寻址的话,那么也必须要去开启或确认寄存器是64位的以及访问新增寄存的问题。
- 问题3:如何去访问新增加的几个寄存器呢?那么也必须要有方法去访问增加的寄存器?
那么在64位Long模式下,为什么不将操作数的Default Operand-Size设计为64位呢?那是由于体系限制,本来AMD64就是在x86的基础上扩展为64位的。x86体系当初设计时就没想到有会被扩展到64位的时候。所以在Segment-Descriptor(段描述符)里就没有可以扩展为64位的标志位。DS.D位只有置1时是32位,清0时为16位,这两种情况。
AMD在保持兼容的大提前下,只好令谋计策,AMD的解决方案是:增加一个64位模式下特有Prefix,以起到扩展访问64位的能力。这就是 REX prefix。
REX prefix 的具体格式及含义
REX prefix的取值范围是:40 ~ 4F(0100 0000 ~ 0100 1111),来看下原来opcode取值范围的40 ~ 4F的是什么指令:
Opcode为40 ~ 47在x86下是inc eax ~ inc edi 指令,48 ~ 4F在x86下是dec eax ~ dec edi 指令。在64位模式下,40 ~ 4F 就已经不是指令而变身为 prefix了。

如上表:
- REX.W域是设定操作数的大小(Operand-Size),当REX.W为1时,操作数是64位,为0时,操作数的大小是缺省大小(Default Opeand-Size)。这就解决了访问64位寄存器的问题。
- REX.R域是用于扩展ModRM字节中的R(Reg)域,ModRM中的Reg域除了对Opcode的补充外,是用来定义寄存器的编码,即寄存器值。REX.R将原来3位的寄存器ID(000 ~ 111)扩展为4位(0000 ~ 1111),这就解决了访新增寄存器的问题。
- REX.X域是用于扩展SIB字节中的Index域,SIB中的Index域是指明Index 寄存器的编码,即ID值。这就解决了寄存器寻址内存中使用新增寄存器的问题。
- REX.B域是用于扩展ModRM字节中的r/m域和SIB中的Base域,SIB中的Base域指明Base寄存器编码即ID值。这就解决了寄存器寻址内存中使用新增寄存器的问题。
看个例子:
1 | 40a093: 4c 89 ee mov %r13,%rsi |
mov %r13,%rsi的机器码是: 4c 89 ee, 原来查找寄存器的 ModR/M 字段从 REX的字段上 扩展了 1 bit, 如果用64位的寄存器,查表如下:
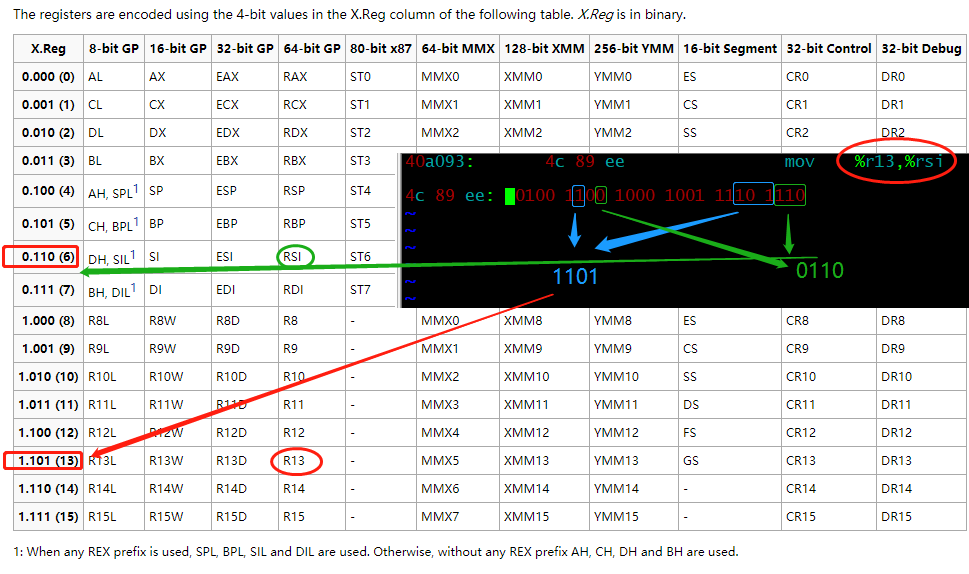
查询的表格见:
https://wiki.osdev.org/X86-64_Instruction_Encoding#Registers
RIP-Relative Addressing
一种新的寻址形式,即RIP相对(相对指令指针)寻址,是在64位模式下实现的。通过在下一条指令的64位RIP上添加位移来形成有效地址。
在IA-32体系结构和兼容模式下,相对于指令指针的寻址仅在控制传递指令中可用。在64位模式下,使用ModR / M寻址的指令可以使用RIP相对寻址。如果没有RIP相对寻址,则所有ModR / M模式都会相对于零寻址存储器。
在64位模式下,将ModR / M Disp32(32位位移)编码重新定义为RIP + Disp32,而不是仅位移。

The ModR/M encoding for RIP-relative addressing does not depend on using a prefix. Specifically, the r/m bit field encoding of 101B (used to select RIP-relative addressing) is not affected by the REX prefix. For example, selecting R13 (REX.B = 1, r/m = 101B) with mod = 00B still results in RIP-relative addressing. The 4-bit r/m field of REX.B combined with ModR/M is not fully decoded. In order to address R13 with no displacement, software must encode R13 + 0 using a 1-byte displacement of zero.
RIP-relative addressing is enabled by 64-bit mode, not by a 64-bit address-size. The use of the address-size prefix does not disable RIP-relative addressing. The effect of the address-size prefix is to truncate and zero-extend the computed effective address to 32 bits.
如何识别各种指令格式
以上介绍了各种指令的格式,目前我们服务器 一般都是用的是 Intel i7 64位的 CPU了, 指令集有几百个,opcode 有一个字节的,两个字节、三个字节的,还有各种前缀后缀, 给出一串二进制判断是什么指令以及操作数 是个查表的过程,已经有 反汇编器帮我们实现了识别的逻辑。
反汇编器
常用的反汇编器有很多:
- udis86
- capstone
- Distorm
https://awesomeopensource.com/projects/disassembler 网站列出了各种语言的和系统的反汇编器。
1 | [root@VM_8_16_centos udcli]# echo "FF 25 00 00 00 00 12 34 56 " | ./udcli -64 -x -att |
回到上面的问题,我们通过反汇编器找到 rip relative相关的指令, 找到 offset后,修改之,就完成了 inline hook 部分指令失效的fix。
详细可以参考: https://github.com/stevemk14ebr/PolyHook
整体流程
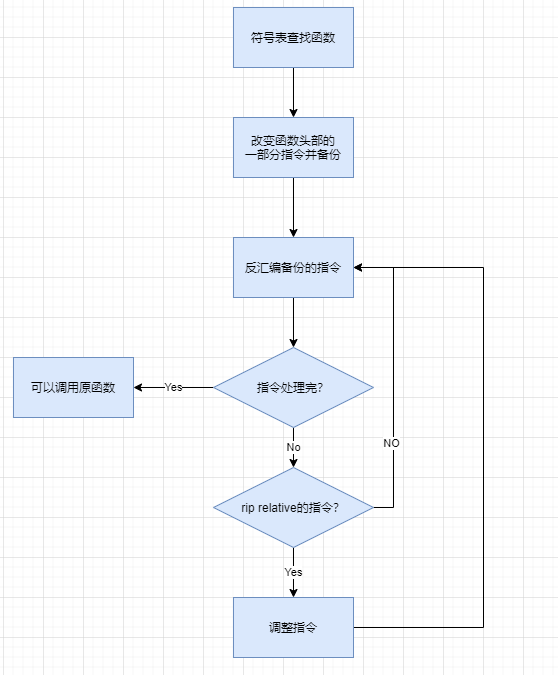
REF

