消息队列的特征
消息队列在存取消息时,必须要满足三个需求,分别是
- 消息保序
- 处理重复的消息
- 保证消息可靠性
消息保序
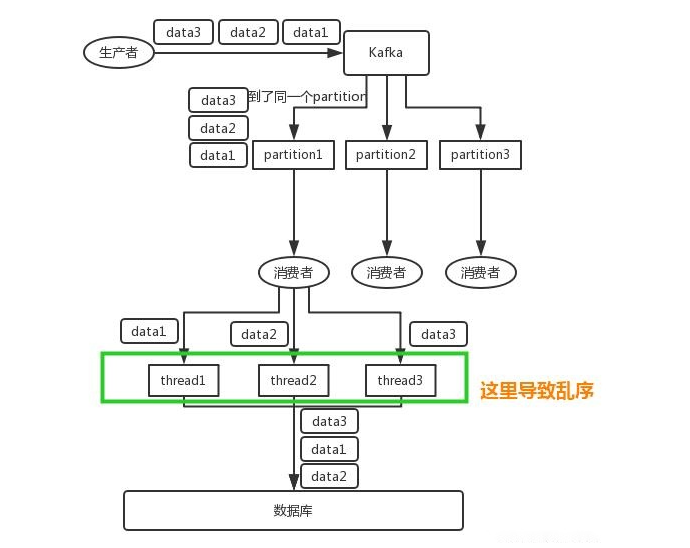
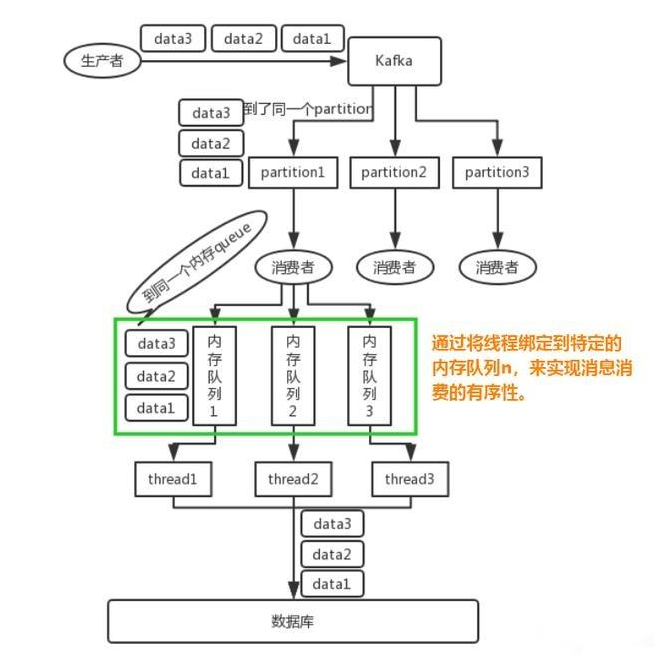
对于 单队列,单进程的queue, 是满足先入先出的特点的,本身是有序的,但是如果有多个队列或多个消费者线程的时候,可能会产生乱序的问题。
kafka的例子:
stream的缺点就是在redis内部,stream就是一个单一的key,如果不对key进行分片,那么stream的容量被限制在单个redis的实例,
当然我们可以使用redis cluster对stream的key进行分片,实现类似kafka多partition的概念,但是由于redis cluster的一些限制,需要解决redis原生命令不支持跨slot操作的问题,
当然经过合理的设计,这并不是一个很大的问题,但是也需要解决,因此如果mq中的数据过于庞大,单个redis实例已经无法容纳,我们需要对stream的key进行分片并解决一些问题,这增大了业务实现的难度.
重复消息
比如 RabbitMQ、RocketMQ、Kafka,都有可能会出现消息重复消费的问题,正常。因为这问题通常不是 MQ 自己保证的,是由我们开发来保证的。挑一个 Kafka 来举个例子,说说怎么重复消费吧。
Kafka 实际上有个 offset 的概念,就是每个消息写进去,都有一个 offset,代表消息的序号,然后 consumer 消费了数据之后,每隔一段时间(定时定期),会把自己消费过的消息的 offset 提交一下,表示“我已经消费过了,下次我要是重启啥的,
你就让我继续从上次消费到的 offset 来继续消费吧”。
但是凡事总有意外,比如我们之前生产经常遇到的,就是你有时候重启系统,看你怎么重启了,如果碰到点着急的,直接 kill 进程了,再重启。这会导致 consumer 有些消息处理了,但是没来得及提交 offset,尴尬了。重启之后,少数消息会再次消费一次。
当收到一条消息后,消费者程序就可以对比收到的消息 ID 和记录的已处理过的消息 ID,来判断当前收到的消息有没有经过处理。如果已经处理过,那么,消费者程序就不再进行处理了。这种处理特性也称为幂等性,
幂等性就是指,对于同一条消息,消费者收到一次的处理结果和收到多次的处理结果是一致的。
基于 Streams 的消息队列解决方案:
- XADD:插入消息,保证有序,可以自动生成全局唯一 ID
- XREAD:用于读取消息,可以按 ID 读取数据
可靠性
基于 Streams 的消息队列解决方案:
- XPENDING 命令可以用来查询每个消费组内所有消费者已读取但尚未确认的消息,而 XACK 命令用于向消息队列确认消息处理已完成
在用Redis当作队列或存储数据时,是有可能丢失数据的:一个场景是,如果打开AOF并且是每秒写盘,因为这个写盘过程是异步的,Redis宕机时会丢失1秒的数据。而如果AOF改为同步写盘,那么写入性能会下降。
另一个场景是,如果采用主从集群,如果写入量比较大,从库同步存在延迟,此时进行主从切换,也存在丢失数据的可能(从库还未同步完成主库发来的数据就被提成主库)。
总的来说,Redis不保证严格的数据完整性和主从切换时的一致性。我们在使用Redis时需要注意。
而采用RabbitMQ和Kafka这些专业的队列中间件时,就没有这个问题了。这些组件一般是部署一个集群,生产者在发布消息时,队列中间件一般会采用写多个节点+预写磁盘的方式保证消息的完整性,即便其中一个节点挂了,也能保证集群的数据不丢失。
如果是金融相关的业务场景,例如交易、支付这类,建议还是使用专业的队列中间件。
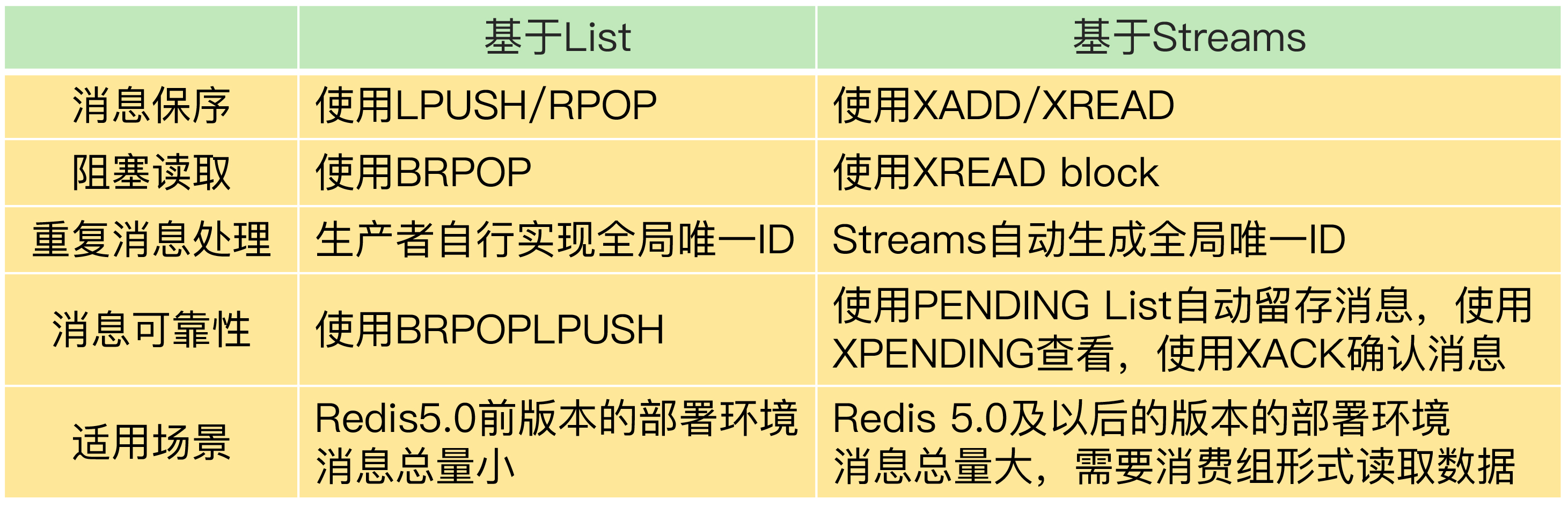
用 List 和 Streams 实现消息队列的特点和区别